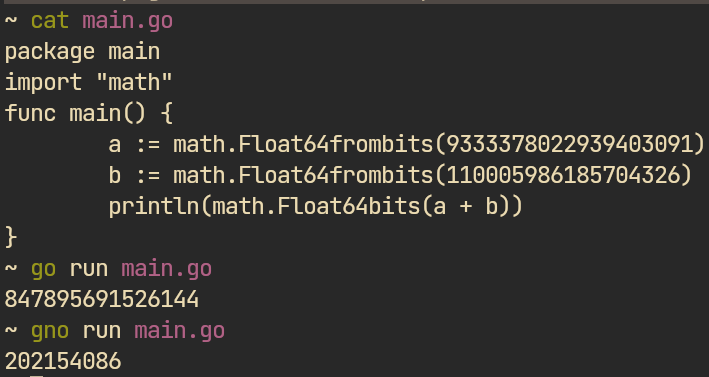
Compiler Testing — Part 2Metamorphic Testing with Verified Identities

Miscompilations and semantic drifts are bugs where the compiler accepts a valid program and silently emits code that behaves differently. On smart-contract platforms this is the bug class that can drain user funds. The post covers differential testing, metamorphic mutations and their sound synthesis — each mutation is proven equivalence-preserving in the developed framework written in Lean4. We will also discuss some of the miscompilations found, some of which resulted in bug bounties.
This post may be useful to you if you:
- Develop, maintain, or test a programming language, especially one targeting smart contracts
- Do security audits on new compilers or runtime environments
- Do security audits of smart contracts and want to include additional checks on compiler correctness that may be an additional attack vector
- Own a smart contract project and want to understand the compiler-level attack surface
The post is organized as follows:
- Background — scope, introduction of miscompilation errors and oracles used
- Verified mutations — the executable semantics, what makes a mutation sound, and the hand-written corpus of identities by category
- Synthesizing mutations — automatically synthesizing sound mutations with Lean feedback
- Testing harness — program generation and mutation, input generation
- Findings – some real-world findings found using this approach, including bug bounty findings
- Conclusion — summary and further work
If you're experienced, here's the whole approach in essence; dive into the interesting parts later:
- Build a Lean4 eDSL implementing a subset of the target language's semantics.
- Hand-write textbook identities and prove them sound in that semantics — we will consider arithmetic over the 256-bit word ring, linear/poly MBA, some QF_BV, and ad-hoc identities that hit common cryptographic builtins and peephole optimizers.
- Use the executable semantics to synthesize more sound mutations (bounded, with ad-hoc filters): generator + bottom-up search + Lean kernel as an oracle — simpler than counterexample-based approaches.
- Run the fuzzing pipeline, leveraging both differential and metamorphic testing.
It is not that hard to build, and — implemented properly — it does find bugs in corner cases that other fuzz-testing tools miss.
Background
The previous post targeted compiler crashes and quality issues only.
This part targets more tricky bugs: semantic drifts and miscompilations. This means that the implementation of the smart-contract/program is correct and matches the specification, but because of the bug in the compiler, the actual implementation behaves differently. The targeted bugs may be located in the compiler, corresponding tooling like linkers and the runtime environment.
Miscompilation bugs
The most popular early article on incorrect compilation is "Reflections on Trusting Trust" by Ken Thompson in 1984 [1]. While the whole idea has been known for years, these bugs are better known nowadays in Web3, where they can easily affect smart contracts with real money.
Miscompilations are invisible to smart-contract auditors – the source code is correct, but the actual implementation diverges because of the bug in the trusted base. Worse, they affect all the contracts uploaded on-chain — any contract containing the specific pattern may misbehave or just imply some interesting behavior.
The only exploited bugs so far are the Vyper non-reentrancy hack ($69.3M) and the Cetus hack ($213M) – not in the compiler but related to unexpected semantics in the math library. Other bugs could have caused losses but were fixed before being exploited, such as the TSTORE-poison codegen bug in solc and the billion-dollar Move verifier bug.
That's why compiler bugs are worth hunting.
Oracles
The main problem when hunting miscompilations is how to detect when the program miscompiles. When working with ICE, you get the oracle for free: if the compiler panicked, you got a bug. With miscompilations you have to understand how the compiled program should behave and what the correct behavior is.
In fuzzing, this problem is solved by the oracle: a part of the tool that decides whether a program's output is correct. There are different approaches, but we will consider the ones we use: differential testing and metamorphic testing.
Differential testing
The key idea of differential testing: execute another implementation of SUT with the same inputs and compare the results.
For compiler testing we could use different strategies, to name some:
- Different implementation of the same language for a different platform (e.g.
resolcfor Polkadot andsolcfor Ethereum) - The same compiler with different options (e.g. different optimization passes enabled)
- Different underlying platform (e.g.
solc-compiled EVM bytecode may be executed onevmoneandrevm) - Emit semantically equivalent code for similar languages and test the execution (e.g. TON supports two languages with nearly identical semantics)
- Create a concrete interpreter for differential testing (common approach used e.g. in Solidity and Vyper)
- Use the previous version of the same compiler to hunt regression errors
- Dump IR after different optimization passes and prove its equivalence using SMT (essentially Alive2 is about this [2]; for EVM there is HEVM, which could be used for the same task)
Differential testing is simple and does not require any elaboration. It is free when you already have a second implementation meant to share the same semantics. But the question is how to generate meaningful and diverse enough programs to find bugs. This is a part of what the metamorphic relation brings to us.
Metamorphic testing
Metamorphic testing relies on a metamorphic relation (MR): a rule for how changing the input should change the output, so you can catch a bug without knowing the expected result.
Metamorphic testing, then, is testing through MR: run the program on MR-related inputs and flag a bug if the outputs violate the relation. For compiler testing this means: apply some mutations that create a program with the same observable behavior, but with different code.
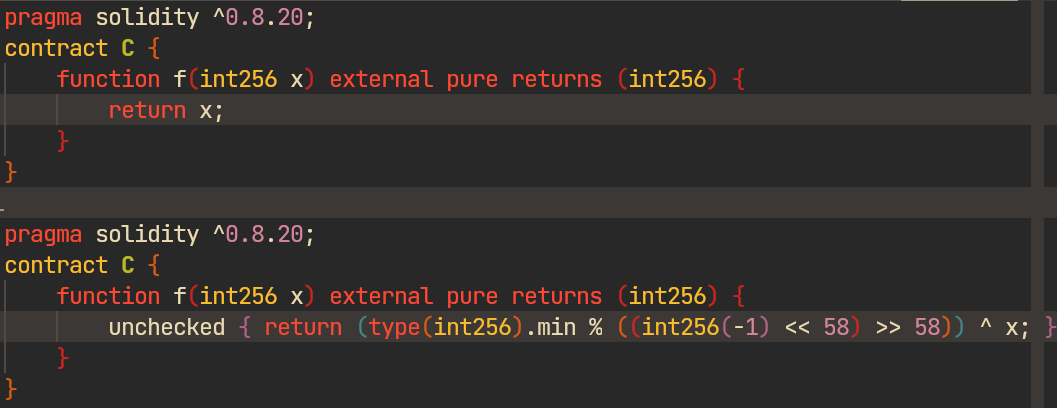
return x identity but return a different result (revive#524)This solves two problems:
- Program generation – the program generator may be utterly simple; MR does the rest
- The oracle problem – we don't need to know the exact result, only that MR holds
Scope
We will focus on a simple subset of the actually used Lean eDSL to limit the scope and target arithmetic-only bugs. These naturally trigger optimizer bugs, especially in peephole optimizers and constant folding, and some infrastructure in the compilation pipeline was also affected by the demonstrated findings.
Now consider how we can define semantics and build the mutations over it, because that's the core of the tool.
Verified mutations
The main component of the tool is a framework in Lean that implements:
- Executable semantics – generic enough to be extended to a specific language's semantics.
- A library of hand-written mutations.
Lean4
While similar approaches have been implemented in different works, people usually prefer SMT for similar projects.
Lean was chosen because:
- That's a full-blown functional language with typeclasses, polymorphism and meta-programming which enables us to create a reusable framework.
- Lean provides tactics beyond
bv_decidewhich help in proving some mutations. - Lean usage became less painful with LLMs available: while the core of the tool and the EVM part are hand-written, LLMs enable us to prove some parts of the source code, automating hard work efficiently, and help to scale the existing project to other languages and semantics efficiently.
Lean is really nice as a programming language, and it is usable not only for formal verification but even for simpler projects like this.
Executable semantics
Consider a heavily simplified version of the executable semantics in Lean. While it looks like a plzoo cosplay, it is enough to demonstrate the main idea of the approach.
inductive Uop | neg
inductive Bop | add | sub | mul
inductive E (n : Nat) where
| var : Fin n → E n
| lit : BitVec 256 → E n
| un : Uop → E n → E n
| bin : Bop → E n → E n → E n
def denU : Uop → BitVec 256 → BitVec 256
| .neg, a => -a
def denB : Bop → BitVec 256 → BitVec 256 → BitVec 256
| .add, a, b => a + b
| .sub, a, b => a - b
| .mul, a, b => a * b
def den {n : Nat} : E n → (Fin n → BitVec 256) → BitVec 256
| .var i, ρ => ρ i
| .lit c, _ => c
| .un o a, ρ => denU o (den a ρ)
| .bin o a b, ρ => denB o (den a ρ) (den b ρ)
A mutation rewrites a subexpression lhs into rhs. For this total den, one kernel-checked condition makes it sound: den lhs ρ = den rhs ρ for every ρ — that is exactly what ok certifies. The full semantics is partial (division can diverge), where a second condition is also needed: lhs/rhs must mention the same variables. Otherwise x * 0 → 0 breaks when x := 1 / 0 — x * 0 and 0 are value-equal, but dropping x hides the divergence. So, verified here means any divergence we find later is a real miscompile, not a bad rewrite.
The identities considered below are not hard to prove: bv_decide and ring close most, simp and rfl the definitional ones. decide and omega are not for the identities themselves — they handle other cases, like control flow and index bounds.
The SoundMut type
In code, a mutation is that rewrite and its proof. fn tries to rewrite a node (none if nothing to match for this pattern); ok certifies that if it fires, den is preserved:
structure SoundMut where
fn : {n : Nat} → E n → Option (E n) -- try to rewrite a node
ok : ∀ {n} (e e' : E n) (ρ : Fin n → BitVec 256),
fn e = some e' → den e ρ = den e' ρ -- ...preserving den
fn only looks at one node, but the harness applies it at every subterm of the program — and ok lifts to soundness at each of those positions.
Now consider a couple of hand-written arithmetic mutations to show how it works, starting from the simplest.
Bittwiddling hacks and nat ring operations
These are simple textbook identities. Each becomes a SoundMut: fn matches the pattern and rewrites it; ok proves den is preserved.
Here is an example:
-- x * 2 -> x + x (strength reduction)
def mul2addFn {n} : E n → Option (E n)
| .bin .mul a (.lit 2) => some (.bin .add a a)
| _ => none
def mul2add : SoundMut where
fn := mul2addFn
ok := by intro n e e' ρ h; unfold mul2addFn at h; split at h
· injection h with h; subst h; simp only [den, denB]; bv_decide
· exact absurd h (by simp)
Bit-level identities (two's complement -x = ~x + 1, De Morgan, …) plug in the same way once E is extended with the bitwise operators.
Good sources of such mutations to add are:
Mixed-boolean arithmetic
Mixed-boolean arithmetic (MBA) is a class of expressions that mix arithmetic operators (+, -, *) with bitwise ones (&, |, ^, ~) over fixed-width integers. A good introduction to it is the series of blog posts by Justus Polzin.
Typically, MBA is used in the process of obfuscation and deobfuscation. Obfuscation is defined as a process which consists in transforming a program in order to make its analysis difficult and costly, while preserving its observable behavior. Essentially, it does what we need for metamorphic testing – creates identities.
MBA identities are exactly the obfuscated-looking shape a stacked mutant turns into. The linear ones (with constant coefficients) are hand-written and bit-blast cheaply with bv_decide:
-- a + b -> (a ^ b) + 2*(a & b) (addition as xor + carry)
def addXorFn {n} : E n → Option (E n)
| .bin .add a b => some (.bin .add (.bin .xor a b) (.bin .mul (.bin .and a b) (.lit 2)))
| _ => none
def addXor : SoundMut where
fn := addXorFn
ok := by intro n e e' ρ h; unfold addXorFn at h; split at h
· injection h with h; subst h; simp only [den, denB]; bv_decide
· exact absurd h (by simp)
-- a ^ b -> (a | b) - (a & b)
def xorOrAndFn {n} : E n → Option (E n)
| .bin .xor a b => some (.bin .sub (.bin .or a b) (.bin .and a b))
| _ => none
def xorOrAnd : SoundMut where
fn := xorOrAndFn
ok := by intro n e e' ρ h; unfold xorOrAndFn at h; split at h
· injection h with h; subst h; simp only [den, denB]; bv_decide
· exact absurd h (by simp)
Polynomial MBA (products of variables) blows up bv_decide — the variable multipliers don't enable bit-blasting — so those are bridged into ring form and proven with ring, mostly via synthesis.
QF_BV
QF_BV (quantifier-free bit-vector logic) covers comparisons and predicates lowered to bit operations — the part bv_decide settles directly by bit-blasting.
The hand-written corpus implements the standard lowerings; comparisons return a 0/1 word, for example:
-- a <s 0 -> (a >>> 255) & 1 (sign-bit extract)
def slt0Fn {n} : E n → Option (E n)
| .bin .slt a (.lit 0) => some (.bin .and (.bin .lshr a (.lit 255)) (.lit 1))
| _ => none
def slt0 : SoundMut where
fn := slt0Fn
ok := by intro n e e' ρ h; unfold slt0Fn at h; split at h
· injection h with h; subst h; simp only [den, denB]; bv_decide
· exact absurd h (by simp)
Domain-specific mutations
Some mutations are implemented based on the systems that were tested and the underlying stack. For example:
- Cryptographic primitives (e.g. EVM-like mulmod which actually got a real-world finding)
- Optimization-specific patterns from Solidity compilers, especially the Yul backend
- LLVM InstCombine — if you catch some bug in LLVM on the way — it may also affect contract compilers, like the known g++ bug causing ICE in the Solidity compiler
An example from the InstCombine corpus — LLVM's own peephole rewrites like this:
-- InstCombine: x + x -> x << 1 (strength reduction)
def addSelfFn {n} : E n → Option (E n)
| .bin .add a b => if a = b then some (.bin .shl a (.lit 1)) else none
| _ => none
def addSelf : SoundMut where
fn := addSelfFn
ok := by intro n e e' ρ h; unfold addSelfFn at h; split at h
· split at h
· rename_i hab; injection h with h; subst h; subst hab
simp only [den, denB]; bv_decide
· exact absurd h (by simp)
· exact absurd h (by simp)
While there are many ideas on how to include common mutations, to have a really exhaustive corpus of mutations, you should generate verified mutations automatically. Consider how.
Synthesizing mutations
Hand-writing identities does not scale — the useful mutations hide in corner cases that are hard to fully cover by hand. The solution is to have a script generate mutations and let the Lean kernel decide which proposals are real. The enumerator script suggesting mutations is completely untrusted, and the worst it can do is emit a theorem that fails to compile. Only sound mutations are added to the corpus.
The whole idea is bottom-up search:
- Mirror — a Python copy of the
densemantics used as a fast oracle. - Enumerate — create terms over
a, b, cand a constant menu (integer type boundaries, EC field primes with their sparse coefficients, shift/mask amounts) up to the specified depth, simplest-first. - Fingerprint — evaluate each term on a few adversarial valuations (e.g. corner triples that always probe
0 / -1 / intMin / intMax, plus seeded random) and hash the result vector. Terms that land in the same bucket agree on every probe. - Conjecture — every collision between two structurally different terms becomes a candidate identity. Agreement on a few dozen points is not a proof; it is a guess delegated to the kernel.
It is simpler than the counter-example-based SMT approaches for synthesis used in some works, but works great and solves its task.
Concretely, the loop is small — here it is against the den defined earlier (the enumerator and emitter cut for brevity):
MOD = 1 << 256
wrap = lambda x: x & (MOD - 1) # 256-bit two's complement
# a Python mirror of the (simplified) Lean `den` above
def den(t, env):
match t:
case ('var', i): return env[i]
case ('lit', c): return c
case ('neg', a): return wrap(-den(a, env))
case ('add', a, b): return wrap(den(a, env) + den(b, env))
case ('sub', a, b): return wrap(den(a, env) - den(b, env))
case ('mul', a, b): return wrap(den(a, env) * den(b, env))
# fingerprint = den on a fixed battery of valuations (corners + seeded random)
VALS = [(0, 0, 0), (1, 1, 1), (MOD - 1, 1 << 255, 0), *seeded_random_triples(40)]
fp = lambda t: tuple(den(t, v) for v in VALS)
# enumerate terms simplest-first; a fingerprint collision is a candidate identity
bank = {}
for t in enumerate_terms(maxdepth=4):
f = fp(t)
if f in bank and bank[f] != t:
emit_lean_theorem(bank[f], t) # equal on every probe -> conjecture lhs = rhs
else:
bank.setdefault(f, t)
Each candidate is routed to the tactic that can actually close it and emitted as a Lean theorem the kernel re-checks:
bv_decidefor bitwise, shift, and comparison goals — bit-blasting, cheap unless a large multiplier is involved.ringfor linear and field arithmetic, where 256-bit numerals make bit-blasting explode.ringcan't see bitwise operators, so polynomial MBA identities first cross one-off bridges proven once bybv_decide—x ||| y = x + y - (x &&& y),x <<< k = x * 2^k, ... — that rewrite the bitwise atoms into+, -, *; thenringfinishes.
Comparisons are schema-driven (curated) rather than blind-enumerated, which would just flood the buckets with trivia.
A proven value-fact ∀ ρ, den lhs ρ = den rhs ρ is still only pointwise equality of two fixed patterns. mkSynthMut lifts it into a real SoundMut that fires at any subterm, depth, and substitution:
-- emitted by the synthesizer, then re-checked by the kernel
def slhs_0007 : E 2 := (.un .not (.bin .and (.var 0) (.var 1)))
def srhs_0007 : E 2 := (.bin .or (.un .not (.var 0)) (.un .not (.var 1)))
theorem sval_0007 : ∀ ρ, den slhs_0007 ρ = den srhs_0007 ρ := by
intro ρ; simp only [slhs_0007, srhs_0007, den, denB, denU, Option.some.injEq]; bv_decide
def m_synth_0007 : SoundMut := mkSynthMut "synth_0007" slhs_0007 srhs_0007 sval_0007 (by decide)
A simple structural matcher proposes a substitution σ. The rewrite fires only if DecidableEq confirms subst σ lhs == e — the matcher proposes, the certificate disposes. From there liftValue carries the value-fact into any context, and an occurrence check (by decide) makes sure a diverging argument aborts both sides the same way. The resulting mutation is the same as a hand-written one: same SoundMut type, same machine-checked guarantee.
Testing harness
When we have a library of verified mutations, we can generate a program, apply mutations, and run the differential harness with concrete inputs to ensure the SUT and oracle agree on results. Consider each step in more detail.
Program generation
The program generation logic is absolutely minimal. Typically, the generator creates a couple of pure functions containing a single return, and optionally a couple of constants.
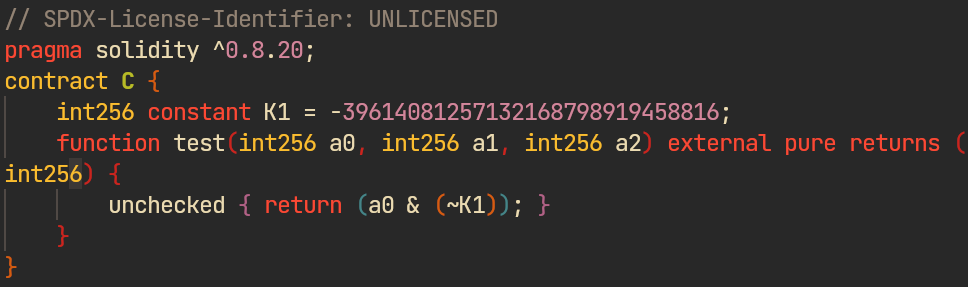
For this seed only one constant and one function were generated. Otherwise, that's just a minimal pure expression which uses inputs to generate some deterministic result. The next step is to apply mutations to it.
Applying mutations
We choose a random number of mutations to apply, choose mutations, stack them and apply. Here is an example result:
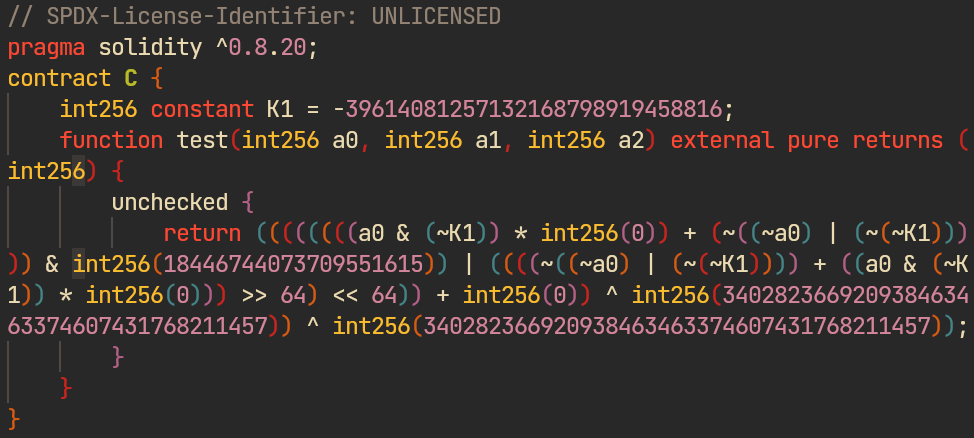
Here four mutations were applied:
- De Morgan:
~((~a0) | (~(~K1))) = a0 & K1 - dead multiply-by-zero terms:
... * int256(0) - 64-bit mask + shift-split-merge:
& 0xffffffffffffffff | (... >> 64 << 64) - XOR self-cancellation against
2^128+1: ... ^ C ^ C
After this, we compile the original program and the mutant for the target (for example, Revive resolc) and execute both programs on the fuzzing harness.
Running harness
The fuzzing harness here is a simple wrapper over the runtime environment that deploys the compiled artifact and executes given inputs over it.
The only challenge there is to choose the best inputs that trigger corner-cases. At the same time, we don't want to have lots of inputs, because it slows down the pipeline.
So, when choosing inputs, the harness:
- Uses a fixed set of combinations likely to break it:
0,1,-1, and the int256 boundsMIN = -2^255,MAX = 2^255-1. - Adds a few inputs picked to cover behaviors of the mutant the fixed set misses — its overflow points, operator corners, etc.
- Adds a couple of pseudo-random inputs for diversity.
The process is just differential fuzzing with concrete values. It beats other differential tools only in the quality and quantity of mutations applied. Let's look at a few findings it made.
Findings
We will consider three bugs found just to show what the findings look like and briefly discuss others and projects that were clean as expected.
Polkadot Revive and ZKsync: mulmod miscompilation
resolc is a Solidity compiler for Polkadot Revive. It compiles Solidity to RISC-V using LLVM, to be executed in pallet-revive on Polkadot parachains. That's a production compiler that produces real-world contracts executed on-chain, and is itself tested by a differential fuzzing test suite.
There are a few bugs found by the tool: some were reported privately, some – publicly, but we will focus on a single bug that affects corner-cases of mulmod. It was reported through the Parity bug bounty program, received a bug bounty for the finding, and was fixed in the 1.2.0 release.
A correct mulmod(a, b, m) always returns a value strictly less than m. Revive routes every mulmod/addmod with m >= 2^128 — all prime-field, elliptic-curve and ZK code, BN254 included — through a hand-written 256-bit long-division helper that is algorithmically wrong: for a class of operands it silently returns a value >= m, with no revert.

mulmod builtin misbehaves, breaking BN254 on corner casesCalling check(2**159, 2**256 - (2**54 + 1), 2**255 + 1):
| backend | mulmod result | < m? |
|---|---|---|
| EVM / geth | 5789604…133313 | yes |
| revive / PolkaVM | 1157920…953282 | no — larger than m |
With m = 5789604…819969, revive returns exactly correct + m: the result simply exceeds the modulus. Over the BN254 scalar field the same defect instead keeps the result < m but with the wrong residue, so it propagates silently through later field arithmetic — which is how it breaks a Bulletproofs inner-product argument when both mulmod operands are attacker-supplied.
ZKsync: the same bug
The interesting story about the implementation is that it is based on the ZKsync Era LLVM compiler, which has had the same bug for years.
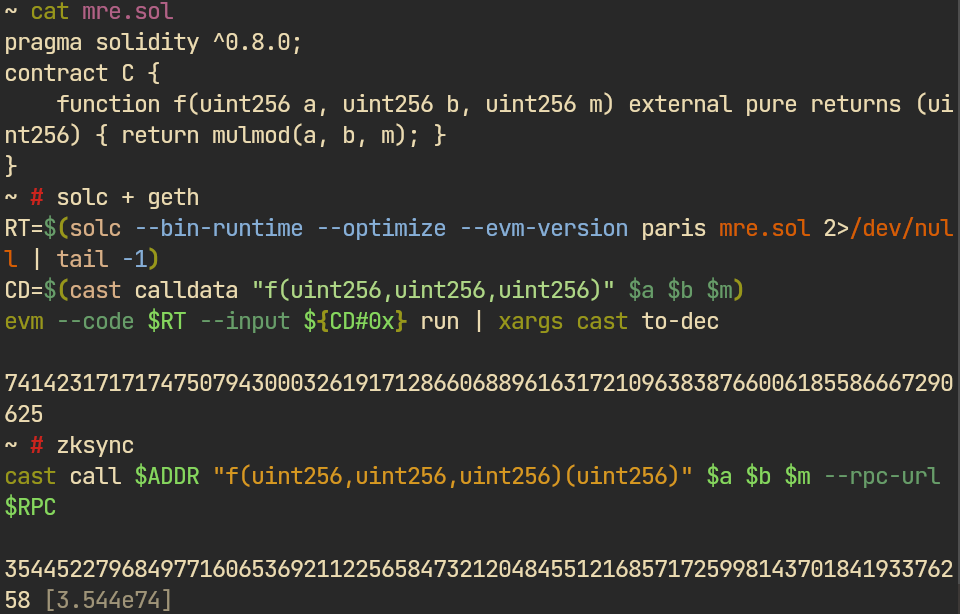
It affects some live contracts, including the ZKsync ecosystem and some dependent projects. But either it is benign, or the affected contracts already have zero TVL – emerging crypto ecosystems move fast, and this bug cannot have any impact there anymore and likely won't be fixed.
Solang: Constant fold << miscompile
Solang's sema-stage constant folder evaluates <</>> with unbounded precision and narrows to the type width only at the end of the expression, while solc masks after every step. So (uint16(0xffff) << 8) >> 8 folds to 65535 instead of 255: when such a constant gates a check, a require that passes on solc/EVM silently reverts on Solang — no diagnostic, every target affected (Polkadot, Solana, Stellar).
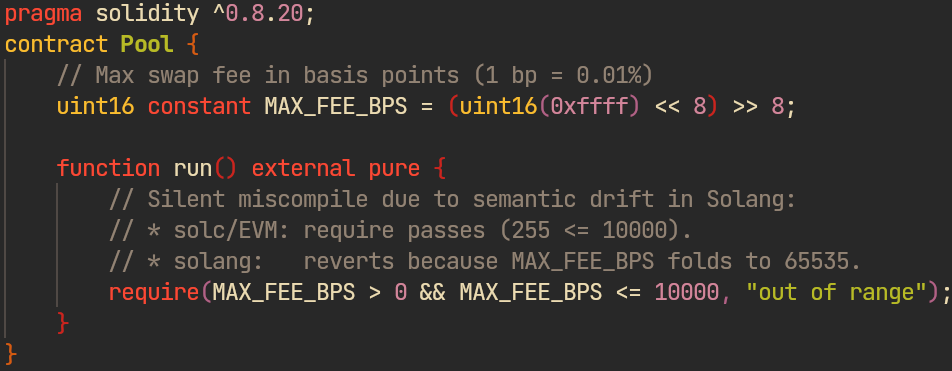
Additionally, the tool highlighted a number of ICEs, including interesting findings like allocation of 10 TiB RAM on compilation, which were not found in the coverage-guided fuzzing campaign.
TON: Miscompile in the shape of a 20-year-old JDK bug
TON languages – FunC and its new version Tolk – are a goldmine of bugs. Two reasons for that:
- Overengineered runtime – the underlying TVM contains a rich set of instructions – complicated and redundant.
- Peephole optimizers – Both compilers try to optimize the generated bytecode because of (1), so they have to deal with many corner cases specific to the platform — that's the main source of bugs (as well as constant folding).
That's why compiler bugs are not in the scope of the bug bounty and even the most creepy bugs take months to be fixed.
The full-blown integration of the Lean framework would be overkill for such a target. It was enough to call an LLM to port some hand-written identities from Lean to Python/z3. This found 19 bugs in total – 13 miscompilations and 6 ICEs – in 2 hours of execution.
An interesting finding among these is the miscompile in the shape of a 20-year-old JDK bug in the TON constant folder:
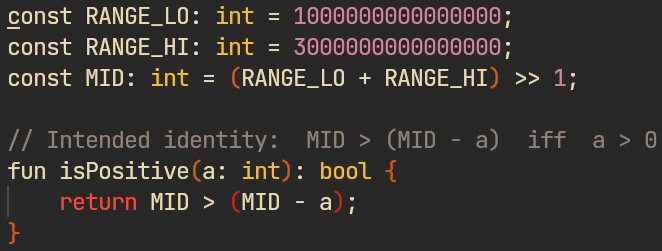
isPositive(-1) == trueOtherwise, the compiler changes control flow, miscompiles in constant folding – the corner cases are unhandled.
Here is the whole 1000-line script reproducing some trivial identities that did the job: github.com/jubnzv/tolk-less.
Other findings
The tool found 15 miscompilations across different projects (not including TON). Some were reported privately and are accepted, still on triage, or ghosted; some were reported publicly and mentioned alongside the blogpost as a demonstration.
But it is not possible to find bugs where there are no bugs. The original Solidity compiler solc did not miscompile on the corpus of identities. The tool did not find anything in the Vyper stable backend, but there were findings like vyper#5012 in the experimental backend, which is not production-ready.
And it would be strange to find anything in audited-to-death projects — in the end these run the multi-billion-dollar infrastructure and should not have such errors.
Conclusion
The post described practical approaches to hunting miscompilations in production compilers — bugs often invisible to simpler program generators and fuzzing tools.
The choice of Lean as an implementation language is justified by language features that let us prove some identities more conveniently, support identities beyond SMT capabilities, and create an extensible framework scalable to other compilers.
While the differential and metamorphic testing approaches are neither complicated nor exhaustive, they become quite efficient when carefully crafted. 1600+ verified mutations stacked together do the job, reaching the most subtle corner cases.
The hand-written mutations library enables us to write rules that trigger specific compiler cases and scale to other platforms when applicable. Mutation synthesis with filters and bounds lets us extend the library for free, using only the executable semantics.
Some real-world findings were demonstrated to prove the feasibility of the approach implemented that way.
Further work
We did not consider high-level language constructs such as control flow, storage operations on mappings/arrays/structs, and anything beyond arithmetic and constants, to keep the scope minimal. Other things like overflow semantics and type widths are generalized by the tool leveraging Lean polymorphism.
There are a couple of approaches to program generation and mutation which work well with the current work:
- Some control flow semantics could be integrated into the described pipeline (with known limitations). The easy wins are core Lean's
iteand let-bindings; others are Moggi monads to express statement-level mutation. - The typical approach is a bottom-up type-driven generator similar to one used in
ghctesting [3]. It could be adapted for imperative languages as well, typically usingArbitrary-like functionality for AST/IR generation. Verified mutations could be applied to generated programs. - Dead [4] and live [5] EMI mutations – while these mostly challenge bugs in optimizers, which are typically intentionally not very aggressive in smart-contract compilers, the technique may improve the overall coverage.
- Some identities and techniques described in obfuscation literature, beyond MBA, are a good source of ideas for new mutations. The idea is the same – keep the observable behavior of the program. Eyrolles' thesis [6] gives a good overview to start with.
References
- Thompson – Reflections on Trusting Trust (1984)
- Lopes et al. – Alive2: Bounded Translation Validation for LLVM (2021)
- Pałka et al. – Testing an optimising compiler by generating random lambda terms (2011)
- Le et al. – Compiler Validation via Equivalence Modulo Inputs (2014)
- Sun et al. – Finding Compiler Bugs via Live Code Mutation (2016)
- Eyrolles – Obfuscation with Mixed Boolean-Arithmetic Expressions: reconstruction, analysis and simplification tools (2017)