Compiler Testing — Part 1Coverage-Guided Fuzzing with Grammars and LLMs

Compiler fuzzing for small languages is a specific problem — few optimization passes, tiny corpora, thin docs. This post covers how coverage-guided fuzzing and LLM-assisted tooling adapt to smart-contract compilers, including a literature overview, related projects, and evaluation results. Found 100+ compiler bugs across Sui Move, Cairo, Solang, Solidity, and Leo. These are not lexer or parser crashes on malformed input — every bug was triggered by structurally valid programs against mature, audited, production compilers.
This post may be useful to you if you:
- Develop, maintain, or test a programming language, especially one targeting smart contracts
- Do structure-aware fuzzing against real-world targets
The post is organized as follows:
- Background — related work, existing approaches, and what makes small-language fuzzing different from C/C++
- Fuzzing harness and configuration — harness design, fuzzer orchestration, tuning for compiler targets
- Custom mutators — leveraging LLMs and tree-sitter grammars in AFL++ mutators
- Corpus and dictionaries — corpus collection, minimization, dictionary construction
- Triage workflow — deduplication, minimization assisted by tools and LLM, and report filing
- Evaluation — all targets, all results, consolidated
- Conclusion and further work — summarizes the post, notes what comes next, lists the published tools
Background
Fuzzing is one of the approaches for finding bugs in compilers. While it does not provide correctness guarantees, it enables you to uncover hidden bugs by generating corner cases that users rarely trigger. Compilers are particularly good targets – they process complex structured input through multiple transformation passes with internal invariants and assumptions.
In the simplest case, the goal is to find compiler crashes – internal compiler errors (ICE). This is easy, because you don't have to write a fuzzing oracle – just execute the compilation pipeline on fuzz data and collect crashes. This post focuses only on ICE; other kinds of errors will be covered in the later part.
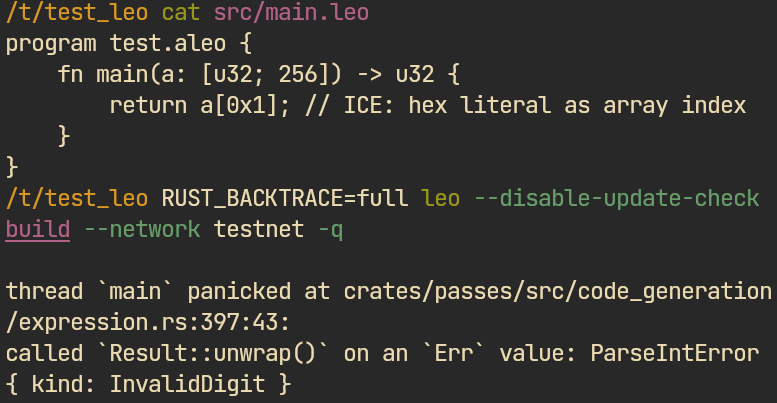
The issues found that way have a low risk for end users – these bugs may crash the tooling (e.g. analyzers, LSP) or the compiler itself, preventing the user from writing planned code and messing up the development process. They don't affect the running program.
The standard fuzzing technique when source code is available is coverage-guided fuzzing. Popular fuzzers operate at byte and bit level — but compilers accept structured input. Pushing random bytes will only hit lexer/parser errors and is far too ineffective to reach later passes. That's why grammar-aware fuzzing exists.
Key idea of grammar-aware fuzzing: generate syntactically correct programs that likely pass the lexer/parser and hit internals of the compiler. This way, we challenge later passes like the typechecker, semantic analysis, and codegen – trying to violate some invariants and assumptions the compiler developers made.
While challenging the lexer/parser is easy, it was intentionally skipped for all the compilers. In small teams and small languages, nobody really cares if input containing 5000 sequential ( symbols will crash the parser. This kind of issue is very common and could be easily found, but it is not worth the time to report or fix, because no sane user will ever write code like this.
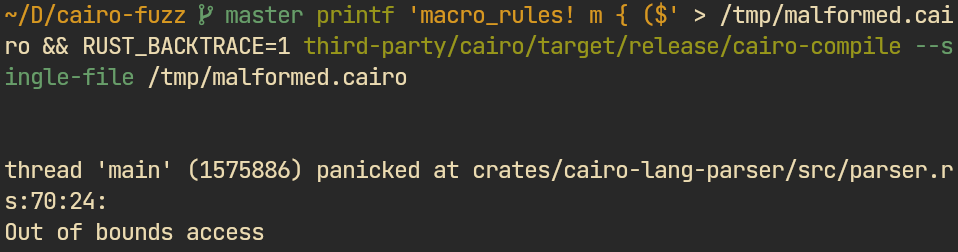
$ in macro rule) → out-of-bounds access. Such bugs were not considered valid and not reported.Most existing research on grammar-aware compiler fuzzing targets C/C++ compilers. Some of these approaches transfer to smart-contract languages, some do not. Here is what makes these targets different:
- Few optimization passes – smart-contract languages focus on correctness, not runtime speed, and are developed by small teams. Program generators (e.g. CSmith or YARPGen) or EMI mutators (like Hermes [7] or XDead [8]) that target miscompilations from aggressive optimizations are of limited use here.
- Simpler execution environments – smart-contract languages target smart-contracts, not general-purpose computing. This means fewer codegen paths and a simpler runtime, which limits the surface for deep codegen bugs.
- Rust as implementation language – many of these compilers are written in Rust, which determines the tooling (cargo-fuzz, AFL++ Rust bindings) and the crash patterns we target: panics, unprotected unwraps, index-out-of-bounds.
- Low popularity – fewer real-world examples are available, which limits corpus collection and approaches that rely on injecting existing code snippets into the fuzzing process [1].
- Often poor documentation – approaches leveraging language documentation or specification [3] are limited, though they work when teams explicitly care about good docs.
- Tree-sitter grammars available – smart-contract languages typically ship tree-sitter grammars for tooling (IDE extensions, syntax highlighting), while ANTLR4 grammars are rare. This makes tools leveraging tree-sitter work well out of the box.
The fuzzing campaign for ICE requires the following parts to be implemented:
- Fuzzing harness – executes the compilation pipeline on fuzz inputs and collects crashes. Needed to run fuzzers in persistent mode and filter out benign panics like stack overflows from parser bugs.
- Custom mutators – implement grammar-aware mutation rules on top of AFL++. Default byte-level mutators can't generate structurally valid programs, so custom mutators are what actually get past the parser.
- Corpus – a collection of seed programs that mutations are derived from. All grammar-aware mutators operate on these inputs, so corpus quality directly determines mutation quality.
- Fuzzing dictionaries – lists of language-specific tokens fed to default mutators (if used). Help byte-level mutations produce valid-looking fragments instead of pure noise.
Fuzzing harness and configuration
A fuzzing harness is a program that sets up fuzzers in persistent mode to receive and process fuzz inputs looking for crashes. Additionally, it sorts out benign panics, like stack overflows typically caused by lexer/parser bugs.
The main fuzzer used is AFL++. It is the most mature, provides an API to write custom mutators, and has the best configuration options. Meanwhile, honggfuzz and libFuzzer use different mutation algorithms, which increases coverage when combined with AFL++.
In some campaigns, honggfuzz and libFuzzer were executed in a single thread and were supplementary; the main work was done by AFL++.
While AFL++ provides an option to sync with foreign fuzzers, you'll still need to implement different harness binaries for each fuzzer.
multifuzz: unified orchestration
To simplify configuration and orchestration of multiple fuzzers, a lightweight orchestrator called multifuzz was implemented. It solves three tasks:
- Unified Rust API to configure all three fuzzers in a single config
- Explicit configuration for all the fuzzers – all env variables and fuzzer arguments must be described explicitly in the config, zero hidden options
- CLI to manage individual fuzzing instances: start, stop, restart
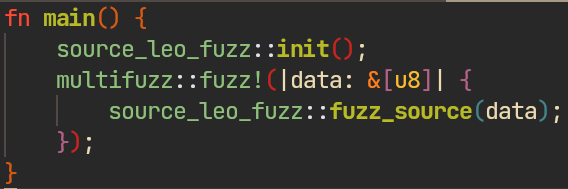
Overall, it adds a zero-overhead configuration layer that sets up a single harness for all three fuzzers and manages them at runtime. Everything is 100% explicit – the tool does not introduce any fancy defaults, so you have to read the documentation.
Here is an example configuration used to fuzz the Sui Move compiler that shows how multiple workers with different options may be configured.
It is optional. Alternatively, you could achieve the same results writing a Makefile or custom scripts and/or running tmux sessions for each fuzzer worker.
Fuzzers configuration
To achieve the best fuzzer performance for grammar-aware testing, the following options were used:
- Selective instrumentation – used to focus fuzzing on specific places in the source code, like recently added features in the compiler. The approach used AFL++ partial instrumentation and is well described in [2] and the documentation.
- No complex byte level mutators were used – cmp-log (or redqueen [6]), fuzzers involving symbolic execution, and Angora (which uses taint traces from inputs) were all skipped, since they were designed to target bit/byte-level mutations. For grammar-aware fuzzing this does not give much benefit, and considering the execution overhead, it slows down the fuzzer.
- Timeouts – compilers are slow, and some mutations may generate code that increases compilation time, e.g. by hitting constant evaluation or generating many entries. The timeout was typically set around 1000ms – enough to keep the corpus clean and avoid cluttering it with useless inputs.
- Memory limits – some targets eat RAM; a special case is Cairo, which uses Salsa – an incremental computation library with its own cache. Other projects may also consume a lot of memory when dealing with large generated inputs. The
-moption is required.
Otherwise, the fuzzing process relies mostly on custom mutators. Fuzzer configuration follows the AFL++ documentation.
Custom mutators
Recent versions of AFL++ provide Rust API bindings to write custom mutators, which simplify development — smart-contract languages are often written in Rust, so you can trigger their internals (e.g. parser, AST) directly from the custom mutator.
Ad-hoc custom mutator
The first attempt was simple: after reading the experiment conducted by Alex Groce [13], the idea was to create a Move-specific AFL++ custom mutator. The result is a small mutator written in C that swaps common language symbols (e.g. { and [), replaces and deletes code blocks, and provides some Move-specific mutations. It uses the custom mutator API and does not fork AFL++.
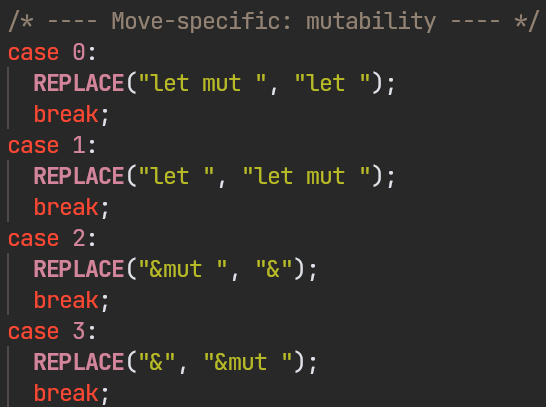
The problems with this approach:
- To be generic enough to target all C-style-syntax compilers, it has to sacrifice language-specific patterns
- It relies heavily on a good corpus
- It is too focused on havoc-style mutations without respecting program structure
afl-ts: Tree-sitter based AFL++ mutator
Instead of mutating bytes, we could mutate the AST directly. Tree-sitter grammars give you typed nodes to swap, delete, and splice — preserving program structure.
A similar tool and approach already exist in the Rust ecosystem: tree-splicer is used by tree-crasher and ice-maker to find ICEs in the rustc compiler. Similar mutation algorithms are applied in multiple grammar-aware fuzzing projects, which typically use ANTLR4 grammars, uncommon among smart-contract languages. However, tree-splicer is a standalone tool, not an AFL++ custom mutator.
afl-ts mutator integrates grammar-aware mutations into AFL++ as a custom mutator. It is fully configurable via environment variables and works with any tree-sitter grammar built with modern tree-sitter. Instead of tweaking the mutator to add the language as needed in tree-splicer, the user just points to the grammar shared library via the TS_GRAMMAR env variable; the language function name can be set via TS_LANG_FUNC, but the tool can usually deduce it from the grammar filename.
Here is the complete table of mutations it conducts:
| Strategy | Weight | What it does |
|---|---|---|
ts-del | 20 | Delete a named AST subtree |
ts-bank | 20 | Replace subtree with type-compatible one from corpus bank (TSSymbol match) |
ts-add | 20 | Replace subtree with type-compatible one from AFL++'s add_buf |
ts-swap | 15 | Swap two sibling nodes of the same type |
ts-shrink | 10 | Replace node with a same-type descendant (always reduces size) |
ts-lit | 5 | Replace leaf with random literal |
ts-dup | 3 | Duplicate a subtree adjacent to itself |
ts-ins | 7 | Insert a type-compatible bank subtree after a node (grows input, capped at 2x) |
ts-range | 4 | Replace a contiguous run of same-symbol siblings with a same-symbol run from add_buf or 1..3 concatenated bank entries |
ts-chaos | 2 | Bypass the type-safety filter on ts-bank / ts-add / ts-range / ts-kins / ts-stutter: splice a random bank (or add_buf) node into the destination regardless of TSSymbol, or stutter the envelope of any parent around any descendant. Produces deliberately ungrammatical inputs to increase coverage. |
ts-kdel | 10 | Delete 1..3 contiguous children from a run of same-symbol siblings, swallowing one adjacent separator so the remaining list stays well-formed |
ts-kins | 10 | Insert 1..3 same-symbol children at a random boundary of a same-symbol sibling run. Donors come from add_buf, the bank, or a duplicated existing member. Separator is detected from the existing list |
ts-stutter | 4 | Pick a parent P and a same-symbol descendant C, then repeat P's prefix/suffix envelope N times around C (radamsa-style tree stutter). Type-safe by default; chaos mode drops the symbol-equality filter. |
Weights represent the probability of each mutation being applied.
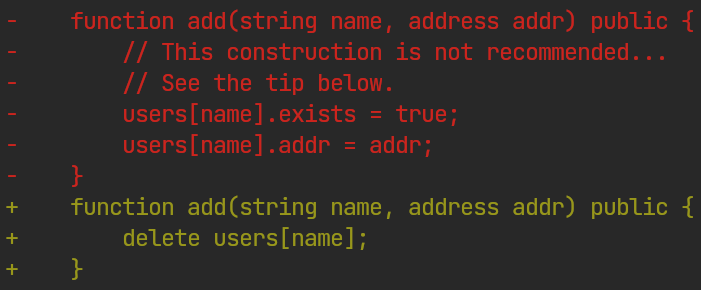
ts-add replaces a function element's contents with another from the same file. ts-bank does the same across files in the queue.Typically, corpus files grow a little when using ts-ins a lot, but not significantly, because the addition must add some coverage to be kept by AFL++.

ts-swap picks matching elements (here, function return types) and swaps them.This mutator alone found lots of bugs; most of the Solang and Solidity findings came from it.
The quality of the tree-sitter grammar matters — grammars producing too many ERROR nodes on valid input degrade mutation quality. Here are the grammars used:
| Target | Tree-sitter grammar |
|---|---|
| Sui Move | tree-sitter-move |
| Cairo | tree-sitter-cairo |
| Leo | tree-sitter-leo |
| Solidity / Solang | tree-sitter-solidity |
MetaMut-style mutators
Beyond tree-sitter mutations, we want language-specific operations that test semantic and codegen passes — without hand-writing them. MetaMut solves this.
The MetaMut paper [5] describes an approach to generating language-specific mutations using LLMs. While the experiment in the paper focused on C and C++ compilers, it can be applied to Rust-based smart-contract languages as well.
We will consider the MetaMut-style mutator developed for Sui Move: MetaMove. While the approach is applicable to other languages, we will focus on Move, which contains 884 unique mutators plus all the scripts needed to demonstrate the approach. While the core idea is similar to MetaMut, the implementation differs in several ways.
From the implementation perspective, it consists of these components:
- Rust mutator library – a small Rust library that lets the model create custom mutators using the compiler's AST without reading the whole compiler codebase on each step. It contains a simplified AST and some logic to call custom mutators.
- Script to invent new mutators – combines mutating operations (
swap,toggle, ...) with all available AST elements, generates descriptions of how each mutation should work, and saves the results. - Script to implement new mutators – takes the descriptions generated by the previous script and the AST from the library, and calls the model to generate mutations with compilation feedback.
- Script to verify the generated mutators – checks whether all of them can be applied and whether they generate syntactically valid code.
The experiment used Sonnet 4.6 to invent and generate the mutators.
Consider the implementation and differences from the original approach in greater detail.
Rust mutator library
The library wraps the Move parser, walks the AST, collecting target categories (expressions, if/match/loop, let bindings, function calls, etc.), and exposes a single MuAstContext that each mutator operates on. Each generated mutator implements a MoveMutator trait with four methods: name(), description(), needs() returning a bitmask of required AST targets, and mutate() that edits the source via byte-offset rewriting — no AST-to-source serializer needed.
Pre-filtering by needs() is the key efficiency trick: the fuzz loop computes the available target kinds once per input, and only mutators whose needs() overlap with those kinds get invoked. A minimal example:
impl MoveMutator for SwapBinOp {
fn name(&self) -> &'static str { "SwapBinOp" }
fn description(&self) -> &'static str { "Swap a binary operator with a compatible one" }
fn needs(&self) -> u32 { TK_BINOP }
fn mutate(&self, ctx: &mut MuAstContext) -> bool {
let binop = ctx.pick_random_binop()?;
let replacement = ctx.compatible_op(binop.kind);
ctx.replace_text(binop.loc, replacement);
true
}
}
Inventing mutators with LLM
The invent phase produces (Name, Description) pairs — each named {Action}{Structure} (e.g. SwapBinOp, ToggleMutability) — that feed the implementation phase. The prompt combines two catalogs: 15 generic actions from the paper plus Move-specific AST structures (BinOp, Match, Ability, Visibility, ModuleDef, etc.).
Mutation actions:
swap — Replace one element with a compatible alternative
remove — Delete an element from the program
add — Insert a new element into the program
duplicate — Copy an element and insert the copy nearby
negate — Invert or negate an element's meaning
modify — Change an element's value or property
inline — Replace a reference with the thing it refers to
wrap — Surround an element with a new construct
unwrap — Remove a surrounding construct, keeping inner content
reorder — Change the order of sibling elements
lift — Move an element to an outer/higher scope
sink — Move an element to an inner/lower scope
split — Break one element into two separate ones
merge — Combine two elements into one
toggle — Flip a boolean-like property on/off
These are generic enough to apply to smart-contract languages as-is. The prompt explicitly asks for syntactically valid mutations only — anything that fails to parse is rejected later in the Validating phase.
The LLM occasionally hallucinates impossible combinations (e.g. negate ModuleDef) and invents descriptions to fit. That's fine for fuzzing: the mutator still changes program structure and opens new paths, and the Validating phase catches anything that doesn't actually modify code or produces invalid syntax. Here's how negate ModuleDef got interpreted:
"Find two
module NAME { ... }declarations in the same file and swap their identifiers, breaking fully-qualified callers and exercising the resolver's duplicate-symbol / shadowing paths."
Differences from the paper:
- Batched generation — 8 operations per target per prompt, saves tokens
- Caching and skip logic for batches that failed in the first iteration
- A configuration option to prioritize specific target structures (e.g. recently-added
enum/matchfor Sui Move)
Implementing mutators
The implement phase turns each (Name, Description) pair into a compiled Rust mutator registered in the driver. The prompt contains the μAST API reference and a reference implementation (SwapBinOp). The LLM returns Rust code as text — it has no filesystem access. The generation script writes each response to src/mutators/{name}.rs, runs cargo check, and on failure sends the code plus compiler error back for a refinement pass (up to 10 rounds). Mutators that still don't compile are dropped.
Mutator quality varies — many are simple, some are hallucinated. That's fine at scale: each target project has 700–1000 combination ideas to invent mutators, and the Validating phase filters the ones that don't actually modify code or generate garbage. About 7% of mutators needed manual fixes after validation to become useful.
Some mutators are primitive but effective. WrapExpressionStmt, generated for Leo, found 4 ICEs despite its simplicity:
//! WrapExpressionStmt: Wrap an expression statement in an assert or call.
impl LeoMutator for WrapExpressionStmt {
fn name(&self) -> &'static str { "WrapExpressionStmt" }
// Generated by the model in the Invent phase
fn description(&self) -> &'static str {
"Wraps an expression statement in an assert or redundant call to \
test type-checking and circuit generation on nested expressions"
}
fn mutate(&self, ctx: &mut MuAstContext) -> bool {
// ... pick an expression from one of the statements if available
// Wrapping the expression found
let wrapped = match ctx.rand_index(10) {
0 => format!("assert_eq({}, {});", expr, expr),
1 => format!("assert_neq({}, 0u32);", expr),
2 => format!("assert({} == {});", expr, expr),
3 => format!("let {} = {};", ctx.generate_unique_name("_w"), expr),
};
ctx.replace_text(target, &wrapped);
true
}
}
Validating mutators
The implement phase only guarantees compilation — not useful behavior. The validation script runs each registered mutator against clean source files from the corpus and classifies the output via move-check:
- Sample N compilable files from the corpus (no parser/lexer errors in baseline)
- Apply each mutator to K files with different seeds (parallel workers)
- Classify resulting errors by
move-checkcategory:- category 1 (parser/lexer) → invalid syntax, mutator rejected
- categories 2-4 (name resolution, unbound variables, type errors) → acceptable, these are exactly the passes we want to test
- Flag mutators that never apply (always no-op, wasting CPU) — an example: a generated top-level-declaration mutator that looked for
useamong function statements
The script also highlights gaps in the corpus – if a mutation never applies, the needed construction is likely missing from the corpus.
Conclusion
Having hundreds of LLM-generated mutators challenging semantic and codegen passes almost for free is a big win for compiler fuzzing — it opens new paths and increases coverage without hand-writing a program generator or spending time on custom coverage-guided tooling.
It works best when combined with other grammar-aware mutators like the tree-sitter splice mutator, which adds randomness and uncovers more subtle cases.
Built-in AFL++ mutators
AFL++ ships with several custom mutators in its distribution. Multiple mutators can be stacked via AFL_CUSTOM_MUTATOR_LIBRARY — different mutation algorithms hit different paths, so combining a grammar-aware mutators with byte-level alternatives increases overall coverage.
autotokens
A grammar-free token fuzzer that splits input into tokens and shuffles them with different strategies. It learns its token pool from the -x dictionary and CMPLOG, and mutates below the grammar level. Useful as a lightweight complement to afl-ts — it picks up on tokens the grammar-aware mutator does not know (e.g. identifiers present in the corpus but not captured in the AST).
radamsa
radamsa is a general-purpose byte-level fuzzer with several strategies that transfer to compiler fuzzing:
sed-tree-stutter— generates deeply nested expressions (e.g.f(g(h(f(g(h(f(g(h(x))))))))))), often crashing parser stack depth and occasionally triggering typechecker errors.afl-tsimplements the same strategy at the grammar level; radamsa operates at byte level and is more aggressive.rand-as-count— appends largeA-strings, useful for hitting integral-type boundaries and array length checks- Byte-level glyph injection — adds "interesting" symbols (unicode glyphs, control bytes) that crash the lexer/parser. Lexer/parser bugs are out of scope here, but the strategy may be useful if you target them.
- Boundary literal injection — swaps numeric values with edge cases (0, MAX, negative, large numbers) to stress integer overflow paths.
afl-ts'sts-litalready does this at the grammar level.
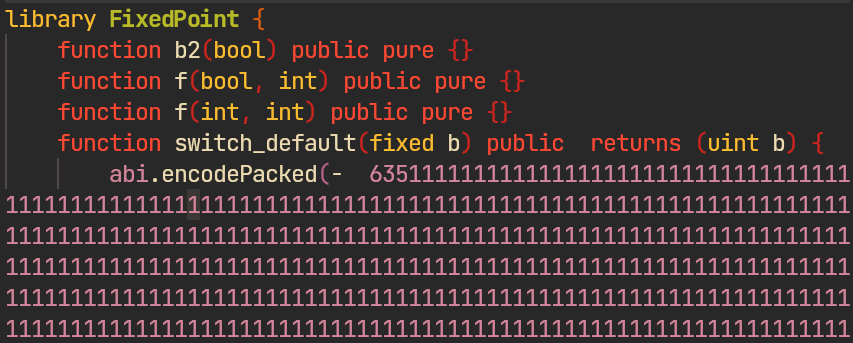
Caveats:
- Most radamsa output is parser/lexer noise that should be filtered during triage
- Very large inputs slow the harness (e.g. constant evaluation on huge numbers)
Not the primary mutator, but running it on one worker adds corpus diversity.
Other grammar-aware fuzzers
There are other open-source fuzzers and custom mutators that may be used to improve the fuzzing campaign. Some of them are integrated to AFL++ while some could be used as an external fuzzers (AFL++ -F flag).
Some fuzzers from papers and open-source projects represent ideas that overlap with the approaches used here. They are mentioned because they may be useful if you are writing your own tooling, or they may be more suitable for the language you are targeting:
- ATNwalk – provides grammar-aware mutations and has built-in AFL++ integration, but is not convenient to use since it requires a quality ANTLR4 grammar.
- Gramatron – grammar-aware fuzzer that operates on grammar automata, which was used for fuzzing an experimental language for the TON blockchain; the main issue was the automaton generation algorithm. Grammars can be generated using this script or manually, but they must be very minimal. This is acceptable for dynamically typed languages like JavaScript as described in the paper [9], but for statically typed blockchain languages the grammars blow up the fixpoint algorithm that generates the automaton.
- Fuzz4All – uses LLM-based generation to fuzz compilers [12]. A good option to extend the corpus or run separately alongside the coverage-guided fuzzer.
- Kitten – an ANTLR4-based program generator that recently found 328 bugs in common compilers. It uses grammar-aware mutations similar to tree-splicer or
afl-ts, with additional strategies like rarity-weighted target selection, kleene-targeted mutations, and top-down grammar generation powered by ANTLR4 [10]. - IssueMut – the same idea as MetaMut, but previous findings are used as a source of mutations [11].
These are interesting sources of related mutation strategies that may be used to improve the tooling.
Corpus and dictionaries
The corpus feeds the mutators. Grammar-aware mutators like afl-ts and MetaMut-style splice, swap, and delete subtrees from corpus entries. Byte-level mutators like radamsa and autotokens extract tokens from the same files. Corpus quality directly determines mutation quality — mutators can only produce what they can see.
A good corpus is small, diverse, and covers a broad surface of the language. Small because havoc and custom splice-style mutators run faster on small files, and oversized entries slow the whole campaign. Diverse because grammar-aware mutators only splice what's present in the corpus — missing language constructs stay unreachable. The tension between "small" and "diverse" is resolved by minimization: collect broadly, then trim to the smallest set that still covers the same paths (discussed in the next subsection).
Collecting corpus files
The most straightforward way to seed the corpus is to collect source files somehwere, remove large and slow inputs and minimize the corpus.
To collect the initial corpus you could start with:
- compiler's test suite and examples
- projects on GitHub
- datasets, e.g. verifier/scan projects often provides information, there are decompiled
sui-packagesfor Sui Move or Zellic dataset of Ethereum contracts
The initial metric to evaluate the corpus coverage is AFL++ stats and code coverage you could get with llvm-cov/gcov.
tsgen: tree-sitter-based generation
Sometimes you get low coverage even after seeding with existing open-source code for the compiler. This happens when the language is powerful enough that not all of its features are actively used, or when new features have just been introduced.
This was the case for Cairo fuzzing. To cover the gaps, a small utility was created: tsgen.
It generates a seed corpus directly from a tree-sitter grammar.json. The generator walks the grammar recursively — at each CHOICE node it picks an alternative, at each REPEAT it picks a count, and at each terminal it samples from a dictionary (optionally augmented by identifiers and literals harvested from real source files). A min-depth pre-pass prevents infinite recursion through self-referential rules (expression → binary_op → expression → ...), and generated programs are validated with the compiled parser to drop anything that doesn't parse.
After generating the corpus, run afl-cmin on it. Practical results: 150k generated Solidity files reduced to ~1300 unique seeds under 1024 bytes each; for the Cairo grammar it was ~700 seeds. That's a lot of seeds for free — the process takes less time than exploring the corpus from the ground up with grammar-aware mutators, and harvesting identifiers from real source files gives better diversity.
LLM-based seed generation with coverage feedback
Another option: generate seeds with an LLM.
Obvious starting points:
- Explore previous findings for the repo and ask the LLM to generate seeds based on them.
- Explore typically bug-prone code based on experience — optimizations, code generation, IR transformations — and ask the LLM to generate code that triggers specific places: constant folding, pattern matching compilation, etc.
- Explore documentation and specification; generate seeds targeting rarely-used or tricky constructions.
- Use
git blameon reachable code paths to generate seeds targeting recently introduced changes.
This works well when you are just starting the campaign and seeding the corpus. After that, its usefulness is limited, because grammar-aware fuzzers will hit most of the paths anyway.
To avoid wasting time and tokens on already-covered paths, involve code coverage: look at which paths are not yet triggered and write a simple script that asks the LLM to generate seeds for specific gaps, then check coverage again in a feedback loop.
While code coverage is not a good metric, it at least lets you make sure your corpus doesn't have complete gaps.
Additionally, approaches like WhiteFox[3] that leverage language documentation for fuzzing were successfully applied for TON. But this requires good documentation and does not scale well when testing multiple compilers.
Another idea that worked: compile your corpus and execute what gets compiled. This reveals bytecode opcodes not covered by the corpus. For example, for Sui Move there were a few extremely rare opcodes related to pattern matching that were absent from 400k decompiled contracts and from the initial corpus, but got covered later this way.
Identifier renaming with tree-sitter
A problem the fuzzer encounters when working with a generated corpus and grammar-aware mutations is the rate of semantic errors. Mutations often shuffle identifiers and code structure, producing lots of "undeclared variable" errors that do not let the fuzzer open new paths.
The solution: write a script that renames all identifiers to deterministic names and saves the result to a separate renamed corpus. Here is a 50-line script doing this with tree-sitter-solidity.
The simplest approach that works: name all identifiers with a uniform pattern, e.g. v0, v1, ... Save this corpus and let afl-ts (in particular the ts-bank mutation) find the errors.
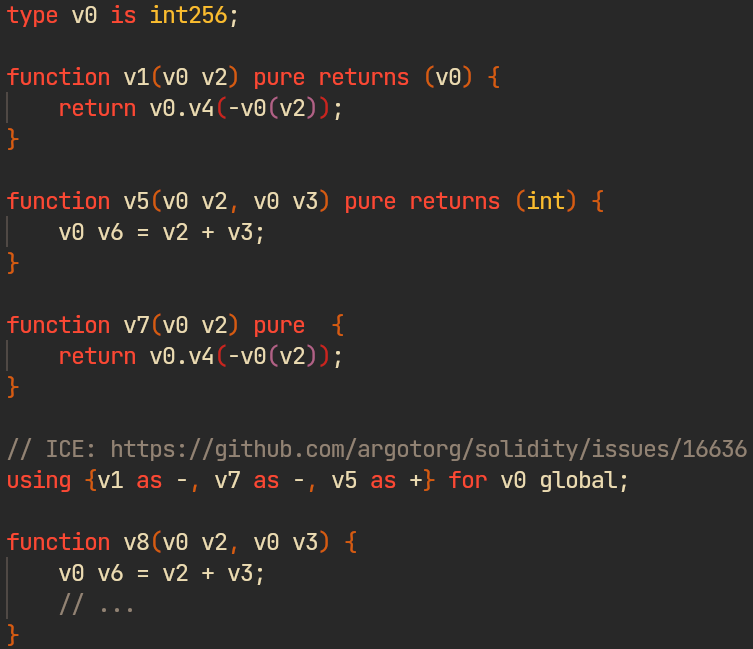
ts-kdel mutation on a renamed corpus → ICE (solidity#16636). Without renaming, this would only trigger an "undeclared variable" error.The approach is straightforward and a similar one is used in the generation routine of CodeAlchemist — a program generator for fuzzing JavaScript engines [4] — for the same purpose.
Additionally, you may want to seed stdlib identifiers or language keywords to challenge the semantic passes.
Dictionaries
A fuzzing dictionary is a list of tokens that the fuzzer inserts into inputs during mutations. All three fuzzers support them: AFL++ via -x, honggfuzz via --dict, and libFuzzer via -dict. A custom dictionary for the language must be used if you run AFL++ without AFL_CUSTOM_MUTATOR_ONLY = 1 — this enables the havoc pass to add meaningful constructions to the code.
Ideas for initial dictionary setup:
- Language's grammar or parser implementation
- Common patterns from documentation and examples
- Names of standard functions and language elements (e.g. possible modifiers or values of
pragma) {,[and similar symbols – these often give interesting results- Constructions involved in previous crashes (find in regression unit tests and/or GitHub search for previous ICEs)
AFL_LLVM_DICT2FILE— auto-extracts string comparisons from the target at compile time. Useful as a supplement, but for compiler fuzzing a hand-crafted dictionary from the language grammar is more effective
Focus on keeping entries atomic; avoid long constructions. For example, instead of let a = &mut x add &mut and let separately – havoc and grammar-aware mutators will figure it out by combining them with existing identifiers and operations.
After running the corpus for a while, it is a good idea to:
- Check coverage – typically you can find operators/constructions that are hit most rarely – add them to the dictionary
- Include constructions from findings made by the fuzzer
Triage workflow
The typical output of a fuzzer is a number of crash and hang (timeout) files — usually big files with lots of irrelevant garbage. Additionally, some crashes are duplicated despite the AFL++ deduplication mechanism, because the same bug may be caused by different syntactic constructions leading to different triggering paths. The goal of triaging is to remove duplicated crashes first, and then minimize the remaining files to a minimal reproducible example (MRE) to report.
The suggested approach:
- Deduplicate crashes with a triage script that analyzes the backtrace of crash/hang callsites
- Minimize the results — manually, using tooling, or with LLMs
- Report filing
Each stage is described below.
Deduplication
A long campaign produces hundreds of crash files for a handful of underlying bugs. Most of them are duplicates of the same panic triggered by different inputs, plus a tail of "benign" panics (stack overflows from parser bugs, intentional TODO errors, etc.) that should not be reported. A short script handles the filtering and grouping.
The algorithm:
- Collect crash inputs from all AFL++ output dirs across workers
- Replay each crash against the harness with backtrace enabled
- Filter out benign panics by matching known patterns (unimplemented features, stack overflows, etc.)
- Extract the throw location from the backtrace
- Normalize the panic message — strip identifiers, source locations, numbers, etc.
- Group and cache crashes to avoid reporting old bugs again
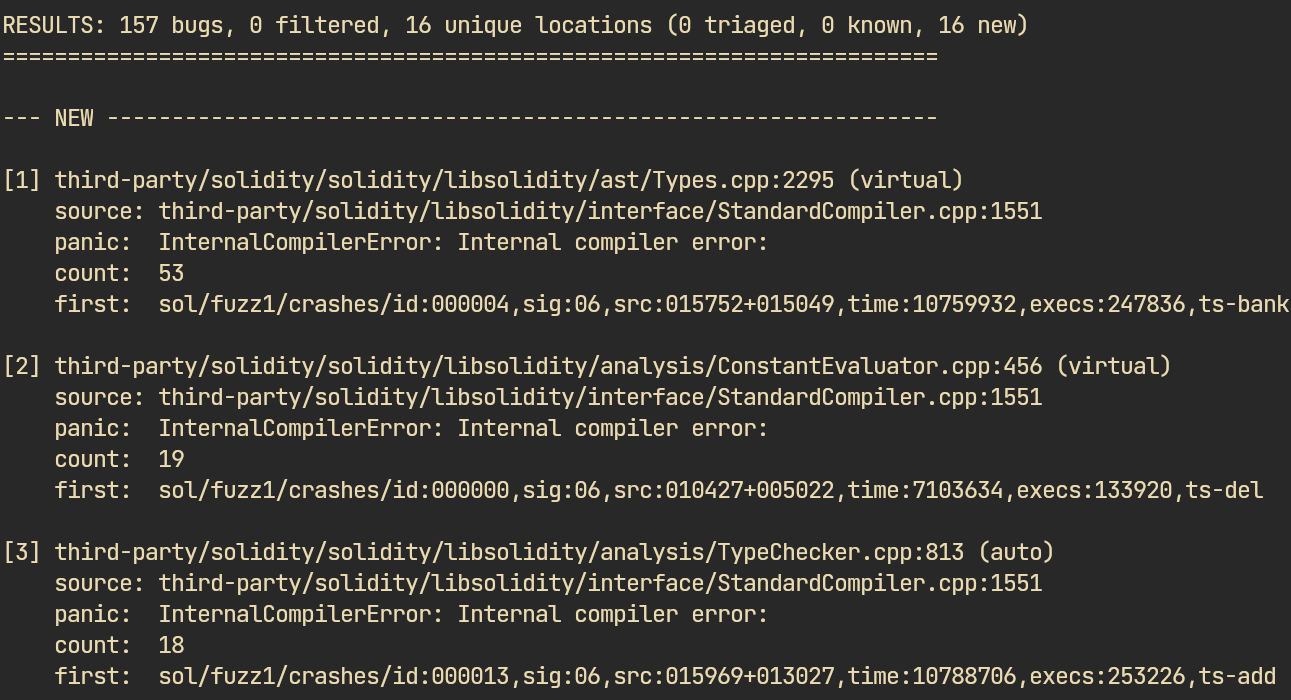
triage.py output for the Solidity campaign: 157 bugs considered unique by AFL grouped into 16 unique locationsWhile the script seems easy to implement with LLMs, make sure it works correctly — especially backtrace parsing and deduplication logic — to avoid losing valid bugs.
An example implementation of such a script for a Solidity fuzzing campaign is available as a gist.
Minimization
When minimizing a crash report manually, use the delta debugging technique — a classic troubleshooting approach.
Among the tools, perses and treereduce can help — both provide grammar-aware reduction. afl-tmin is not a good fit here, because it operates at the bit/byte level and knows nothing about the grammar.
But typically it is not worth your time — you can safely delegate it to an LLM without any extra commands. Two things to watch for: tell the model not to report ASTs recovered after parsing errors; on weird-looking source, it sometimes gives up without reproducing the bug.
Report filing
After deduplication and minimization, you need to check for duplicates against existing issues and write a report.
LLMs work great here, but you need a good prompt:
- Ask the model to check for duplicates with
gh. - Always ask it to reproduce with the real compiler, not with the fuzzing harness.
- Write very concise reports without root cause analysis or suggested fixes — this avoids hallucinations. Don't write anything you did not check by yourself.
First, triage a few reports by yourself, then write a CLAUDE.md triage guide for the model to follow. The complete move-fuzz triage/minimization/reporting prompt is available in the move-fuzz repo.
Evaluation
Here are the results of the campaign. All the findings goes beyond lexer and parser, and triggered by later compilation passes. The findings for Sui Move, Leo, and Cairo are comfirmed and almost all were fixed. Solang and Solidity bugs are under triage at the moment of publishsing (Apr 2026).
Here is the complete table:
The campaign was run on a 2019 Intel i7 U-series and did not take that much time. The goal was to verify the approach, not to find all possible bugs, because running the infrastructure takes resources. These findings were mostly the result of initial corpus generation and quality mutators, and relied on coverage-guided path exploration much less.
Here is the concrete configuration used in fuzzing campaigns:
- Sui Move and Leo were fuzzed mostly with crafted MetaMut-style mutators with additional afl-ts instances. Default AFL++ mutations with custom dicts were applied for some workers. honggfuzz and libfuzzer workers with dicts were applied in 1 thread for some time.
- Solidity and Solang both were fuzzed with
afl-tsworkers mostly because solidity has a large corpus of contracts (e.g. Zellic dataset, lots of regression tests for previous findings in the Solidity repo) and good up-to-date tree-sitter grammar. Default AFL++ mutations with custom dicts were applied for some workers. - Cairo – a MetaMut-style mutators with only mutations for rare constructions and
afl-ts. AFL++ mutations were disabled – since the fuzzing campaign there has extremely low stability and often hits memory limits because of Salsa, any extra executions are expensive because they clutter the corpus making the fuzzing less effective. Thus, only grammar-aware mutations were applied there.
While most of the bugs were found for Sui Move, the approach is maybe more developed there — Sui Move was used as the initial target for fuzzing, as a follow-up to previous work, so the tooling was matured on it before being applied to the other compilers.
There is no precise statistics which custom mutators give the best results nor comparision, while most finding were made by custom MetaMut-style mutations and the afl-ts mutator. This is not a paper evaluating a simple mutator – if your goal is also to find bugs in production code, you should use all the approaches giving you the result with low effort and proven result; combining multiple fuzzers for better corpus diversity and quickier path findng.
Challenges
Some challenges encountered during these campaigns:
- Corpus growth with big files — if you start without a good initial corpus and enable
ts-add, the corpus accumulates oversized entries that slow down the whole campaign. Minimize early and aggressively. - Stability of stateful compilers — Cairo uses Salsa, an incremental computation library. While convenient for tooling development, it complicates fuzzing: the fuzzing state has to be reset every N iterations to avoid OOM, and the MetaMut-style mutator has to be tweaked accordingly. Move and Leo are mostly stable; any minor issues are likely caused by map type usage, but they don't affect the campaign.
- Tree-sitter grammar quality — the whole pipeline (corpus generation,
afl-ts, renaming script) relies heavily on the grammar parsing valid source withoutERRORnodes. Whileafl-tstries to recover fromERRORnodes by inserting syntactically valid code via itsts-chaosstrategy, it is more efficient to run on a clean grammar. - Reproducibility across versions — compilers move fast. An ICE found at HEAD may already be fixed by the time someone triages the report, or the minimizer may shift the behavior to a different internal error. Pin the submodule version in the harness and include the exact commit in every report.
Conclusion and further work
This blogpost shares experience setting up a cheap, fast fuzzing campaign for a non-mainstream language to find ICE. The approach and tooling are reproducible for any compiler.
Two new AFL++ grammar-aware mutators are introduced: afl-ts mutator that works with any tree-sitter grammar, and a MetaMut-style LLM-generated mutator that produces hundreds of language-specific operations from a few prompts. Both proved effective in finding ICE.
Corpus and dictionary setup is covered with practical advice: collect broadly, minimize aggressively, mix manual dictionary entries with AFL_LLVM_DICT2FILE auto-generation. Helper tools (tsgen, validation scripts) are included.
Minimization and triage are LLM-assisted: a CLAUDE.md triage guide handles bucketing and MRE generation, while afl-cmin and perses (or an LLM directly) shrink test cases. Concise prompts without root cause analysis reduce hallucination.
It is like experience sharing – before digging into tools and literature this setup took a couple of weeks; with the approach described here, it takes 1-2 days to get real findings.
We intentionally don't consider approaches to testing that require more time and effort to implement. Oracles, miscompilation, and implementation/specification mismatch errors – these techniques are out of scope and will be described in the next part, since this post is already large as fuck.
Projects discussed
A list of small utilities, mutators, and tools recently published and used in the project:
- jubnzv/afl-ts – grammar-aware AFL++ mutator leveraging tree-sitter
- jubnzv/tsgen – utility for seeding fuzzing corpora using tree-sitter grammars
- jubnzv/multifuzz – unified configuration, orchestration, and Rust API for AFL++/honggfuzz/libFuzzer — no implicit settings or overhead
- nowarp/move-fuzz – fuzzer and mutators for Sui Move
- Fuzzing harness, dictionaries, and scripts
- MetaMut-style mutator with 884 custom mutations for Sui Move
- Ad-hoc Move mutator
- Many ad-hoc scripts demonstrating the approaches — see the post.
Not published yet:
- Leo: fuzzing harness with utilities and MetaMut-style mutator
- Cairo: fuzzing harness with utilities and MetaMut-style mutator
- Solidity and Solang: fuzzing harness with utilities
- Any experiments beyond the scope of the described techniques
If you work on any of the compilers mentioned, reach out — happy to share repo access.
References
- Li et al – Boosting Compiler Testing by Injecting Real-World Code (2024)
- Paaßen et al – Targeted Fuzzing for Unsafe Rust Code: Leveraging Selective Instrumentation (2025)
- Yang et al – WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models (2023)
- Park et al – Fuzzing JavaScript Engines with Aspect-preserving Mutation (2020)
- Ou et al – The Mutators Reloaded: Fuzzing Compilers with Large Language Model Generated Mutation Operators (2024)
- Aschermann et al – REDQUEEN: Fuzzing with Input-to-State Correspondence (2019)
- Sun et al – Finding compiler bugs via live code mutation (2016)
- Tu et al – Beyond a Joke: Dead Code Elimination Can Delete Live Code (2024)
- Srivastava et al – Gramatron: Effective Grammar-Aware Fuzzing (2021)
- Xie et al – Kitten: A Simple Yet Effective Baseline for Evaluating LLM-Based Compiler Testing Techniques (2025)
- Liu et al – Bug Histories as Sources of Compiler Fuzzing Mutators (2025)
- Xia et al – Fuzz4All: Universal Fuzzing with Large Language Models (2024)
- Groce et al – Making No-Fuss Compiler Fuzzing Effective (2022)